介绍
Kube-Prometheus官网
该项目收集Kubernetes清单,Grafana仪表板和Prometheus规则,并结合文档和脚本,以使用Prometheus运算符提供易于操作的端到端Kubernetes集群监控。目前最新版本:v0.10.0,本文使用最新版本进行安装。
Kube-Prometheus主要包括以下组件:
- Prometheus Operator
Prometheus Operator有以下功能:定义Kubernetes资源类型,比如Prometheus,Alertmanager,PrometheusRule等;简化部署和配置;基于Kubernetes标签自动生成target配置。 - 高可用的Prometheus
- 高可用的Alertmanager
- Prometheus Node-exporter
- Prometheus Adapter for Kubernetes Metrics APIs
- kube-state-metrics
- 可视化仪表盘Grafana
| kube-prometheus stack | Kubernetes 1.19 | Kubernetes 1.20 | Kubernetes 1.21 | Kubernetes 1.22 | Kubernetes 1.23 |
|---|---|---|---|---|---|
release-0.7 | ✔ | ✔ | ✗ | ✗ | ✗ |
release-0.8 | ✗ | ✔ | ✔ | ✗ | ✗ |
release-0.9 | ✗ | ✗ | ✔ | ✔ | ✗ |
release-0.10 | ✗ | ✗ | ✗ | ✔ | ✔ |
main | ✗ | ✗ | ✗ | ✔ | ✔ |
环境说明
操作系统:CentOS 7.9.2009
Kube-Prometheus:v0.10.0
Kubernetes:v1.23.5
Docker:20.10.14
一键部署
克隆仓库到本地或者下载指定的版本的Releases包,
下面命令是官方提供的部署命令,可以快速的启动。
kubectl apply --server-side -f manifests/setup
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl apply -f manifests/但是会存在以下问题:
- 官方yaml文件没有归类,不方便之后的集群管理;
- 部分image需要从
k8s.gcr.io拉取,如果是国内机器并没有合适的代理,那就会导致image无法拉取; - Prometheus和Grafana没有配置数据持久化,一旦pod重启或被删除,数据也将被删除;
- 默认的Service无法暴露服务端口到集群外的客户端。
自定义部署
为了针对性地解决上面几个问题,我们进行以下处理
yaml文件分类
Kube-Prometheus v0.10.0一共有84个yaml文件  为了方便管理,根据服务类型将相应的yaml文件进行分类是很有必要的。
为了方便管理,根据服务类型将相应的yaml文件进行分类是很有必要的。
创建目录
mkdir alertmanager blackboxExporter grafana kubeStateMetrics kubernetesControlPlane nodeExporter prometheus prometheusAdapter prometheusOperator根据服务类型yaml文件进行分类
mv alertmanager-* ./alertmanager
mv blackboxExporter-* ./blackboxExporter
mv grafana-* ./grafana
mv kubeStateMetrics-* ./kubeStateMetrics
mv kubernetesControlPlane-* ./kubernetesControlPlane
mv nodeExporter-* ./nodeExporter
mv prometheus-* ./prometheus
mv prometheusAdapter-* ./prometheusAdapter
mv prometheusOperator-* ./prometheusOperator
mv kubePrometheus-prometheusRule.yaml ./prometheus此时目录结构如下
.
├── alertmanager
│ ├── alertmanager-alertmanager.yaml
│ ├── alertmanager-podDisruptionBudget.yaml
│ ├── alertmanager-prometheusRule.yaml
│ ├── alertmanager-secret.yaml
│ ├── alertmanager-service.yaml
│ ├── alertmanager-serviceAccount.yaml
│ └── alertmanager-serviceMonitor.yaml
├── blackboxExporter
│ ├── blackboxExporter-clusterRole.yaml
│ ├── blackboxExporter-clusterRoleBinding.yaml
│ ├── blackboxExporter-configuration.yaml
│ ├── blackboxExporter-deployment.yaml
│ ├── blackboxExporter-service.yaml
│ ├── blackboxExporter-serviceAccount.yaml
│ └── blackboxExporter-serviceMonitor.yaml
├── grafana
│ ├── grafana-config.yaml
│ ├── grafana-dashboardDatasources.yaml
│ ├── grafana-dashboardDefinitions.yaml
│ ├── grafana-dashboardSources.yaml
│ ├── grafana-deployment.yaml
│ ├── grafana-service.yaml
│ ├── grafana-serviceAccount.yaml
│ └── grafana-serviceMonitor.yaml
├── kubeStateMetrics
│ ├── kubeStateMetrics-clusterRole.yaml
│ ├── kubeStateMetrics-clusterRoleBinding.yaml
│ ├── kubeStateMetrics-deployment.yaml
│ ├── kubeStateMetrics-prometheusRule.yaml
│ ├── kubeStateMetrics-service.yaml
│ ├── kubeStateMetrics-serviceAccount.yaml
│ └── kubeStateMetrics-serviceMonitor.yaml
├── kubernetesControlPlane
│ ├── kubernetesControlPlane-prometheusRule.yaml
│ ├── kubernetesControlPlane-serviceMonitorApiserver.yaml
│ ├── kubernetesControlPlane-serviceMonitorCoreDNS.yaml
│ ├── kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml
│ ├── kubernetesControlPlane-serviceMonitorKubeScheduler.yaml
│ └── kubernetesControlPlane-serviceMonitorKubelet.yaml
├── nodeExporter
│ ├── nodeExporter-clusterRole.yaml
│ ├── nodeExporter-clusterRoleBinding.yaml
│ ├── nodeExporter-daemonset.yaml
│ ├── nodeExporter-prometheusRule.yaml
│ ├── nodeExporter-service.yaml
│ ├── nodeExporter-serviceAccount.yaml
│ └── nodeExporter-serviceMonitor.yaml
├── prometheus
│ ├── kubePrometheus-prometheusRule.yaml
│ ├── prometheus-clusterRole.yaml
│ ├── prometheus-clusterRoleBinding.yaml
│ ├── prometheus-podDisruptionBudget.yaml
│ ├── prometheus-prometheus.yaml
│ ├── prometheus-prometheusRule.yaml
│ ├── prometheus-roleBindingConfig.yaml
│ ├── prometheus-roleBindingSpecificNamespaces.yaml
│ ├── prometheus-roleConfig.yaml
│ ├── prometheus-roleSpecificNamespaces.yaml
│ ├── prometheus-service.yaml
│ ├── prometheus-serviceAccount.yaml
│ └── prometheus-serviceMonitor.yaml
├── prometheusAdapter
│ ├── prometheusAdapter-apiService.yaml
│ ├── prometheusAdapter-clusterRole.yaml
│ ├── prometheusAdapter-clusterRoleAggregatedMetricsReader.yaml
│ ├── prometheusAdapter-clusterRoleBinding.yaml
│ ├── prometheusAdapter-clusterRoleBindingDelegator.yaml
│ ├── prometheusAdapter-clusterRoleServerResources.yaml
│ ├── prometheusAdapter-configMap.yaml
│ ├── prometheusAdapter-deployment.yaml
│ ├── prometheusAdapter-podDisruptionBudget.yaml
│ ├── prometheusAdapter-roleBindingAuthReader.yaml
│ ├── prometheusAdapter-service.yaml
│ ├── prometheusAdapter-serviceAccount.yaml
│ └── prometheusAdapter-serviceMonitor.yaml
├── prometheusOperator
│ ├── prometheusOperator-clusterRole.yaml
│ ├── prometheusOperator-clusterRoleBinding.yaml
│ ├── prometheusOperator-deployment.yaml
│ ├── prometheusOperator-prometheusRule.yaml
│ ├── prometheusOperator-service.yaml
│ ├── prometheusOperator-serviceAccount.yaml
│ └── prometheusOperator-serviceMonitor.yaml
└── setup
├── 0alertmanagerConfigCustomResourceDefinition.yaml
├── 0alertmanagerCustomResourceDefinition.yaml
├── 0podmonitorCustomResourceDefinition.yaml
├── 0probeCustomResourceDefinition.yaml
├── 0prometheusCustomResourceDefinition.yaml
├── 0prometheusruleCustomResourceDefinition.yaml
├── 0servicemonitorCustomResourceDefinition.yaml
├── 0thanosrulerCustomResourceDefinition.yaml
└── namespace.yaml
10 directories, 84 files解决k8s.gcr.io镜像拉取失败
k8s.gcr.io因为大陆防火墙的原因,国内网络无法直接访问,所以需要其它方法来获取镜像。这里我们使用DockerHub同步的镜像来解决这个问题。具体方法可以参考下面两种,任选其一即可:
推荐多节点使用!
将文件./kubeStateMetrics/kubeStateMetrics-deployment.yaml中的k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0修改为buall/kube-state-metrics:v2.3.0
将文件./prometheusAdapter/prometheusAdapter-deployment.yaml中的k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1修改为buall/prometheus-adapter:v0.9.1
这种方法不需要修改yaml文件,推荐单节点使用!
docker pull buall/kube-state-metrics:v2.3.0
docker tag buall/kube-state-metrics:v2.3.0 k8s.gcr.io/kube-state-metrics/kube-state-metrics:v2.3.0
docker pull buall/prometheus-adapter:v0.9.1
docker tag buall/prometheus-adapter:v0.9.1 k8s.gcr.io/prometheus-adapter/prometheus-adapter:v0.9.1数据持久化
Grafana数据持久化
首先创建一个PVC,用来存储Grafana数据。在grafana目录中新建一个名为grafana-PersistentVolumeClaim.yaml的文件,并写入以下内容(创建一个名为grafana-pvc且大小为10G的PVC)。
kind: PersistentVolumeClaim
apiVersion: v1
metadata:
name: grafana-pvc
namespace: monitoring
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 8.3.3
spec:
storageClassName: nfs-client
accessModes:
- ReadWriteMany
resources:
requests:
storage: 10Gi此时文件目录结构如下:
.
├── alertmanager
│ ├── alertmanager-alertmanager.yaml
│ ├── alertmanager-podDisruptionBudget.yaml
│ ├── alertmanager-prometheusRule.yaml
│ ├── alertmanager-secret.yaml
│ ├── alertmanager-service.yaml
│ ├── alertmanager-serviceAccount.yaml
│ └── alertmanager-serviceMonitor.yaml
├── blackboxExporter
│ ├── blackboxExporter-clusterRole.yaml
│ ├── blackboxExporter-clusterRoleBinding.yaml
│ ├── blackboxExporter-configuration.yaml
│ ├── blackboxExporter-deployment.yaml
│ ├── blackboxExporter-service.yaml
│ ├── blackboxExporter-serviceAccount.yaml
│ └── blackboxExporter-serviceMonitor.yaml
├── grafana
│ ├── grafana-config.yaml
│ ├── grafana-dashboardDatasources.yaml
│ ├── grafana-dashboardDefinitions.yaml
│ ├── grafana-dashboardSources.yaml
│ ├── grafana-deployment.yaml
│ ├── grafana-PersistentVolumeClaim.yaml # 创建Grafana PVC
│ ├── grafana-service.yaml
│ ├── grafana-serviceAccount.yaml
│ └── grafana-serviceMonitor.yaml
├── kubeStateMetrics
│ ├── kubeStateMetrics-clusterRole.yaml
│ ├── kubeStateMetrics-clusterRoleBinding.yaml
│ ├── kubeStateMetrics-deployment.yaml
│ ├── kubeStateMetrics-prometheusRule.yaml
│ ├── kubeStateMetrics-service.yaml
│ ├── kubeStateMetrics-serviceAccount.yaml
│ └── kubeStateMetrics-serviceMonitor.yaml
├── kubernetesControlPlane
│ ├── kubernetesControlPlane-prometheusRule.yaml
│ ├── kubernetesControlPlane-serviceMonitorApiserver.yaml
│ ├── kubernetesControlPlane-serviceMonitorCoreDNS.yaml
│ ├── kubernetesControlPlane-serviceMonitorKubeControllerManager.yaml
│ ├── kubernetesControlPlane-serviceMonitorKubeScheduler.yaml
│ └── kubernetesControlPlane-serviceMonitorKubelet.yaml
├── nodeExporter
│ ├── nodeExporter-clusterRole.yaml
│ ├── nodeExporter-clusterRoleBinding.yaml
│ ├── nodeExporter-daemonset.yaml
│ ├── nodeExporter-prometheusRule.yaml
│ ├── nodeExporter-service.yaml
│ ├── nodeExporter-serviceAccount.yaml
│ └── nodeExporter-serviceMonitor.yaml
├── prometheus
│ ├── kubePrometheus-prometheusRule.yaml
│ ├── prometheus-clusterRole.yaml
│ ├── prometheus-clusterRoleBinding.yaml
│ ├── prometheus-podDisruptionBudget.yaml
│ ├── prometheus-prometheus.yaml
│ ├── prometheus-prometheusRule.yaml
│ ├── prometheus-roleBindingConfig.yaml
│ ├── prometheus-roleBindingSpecificNamespaces.yaml
│ ├── prometheus-roleConfig.yaml
│ ├── prometheus-roleSpecificNamespaces.yaml
│ ├── prometheus-service.yaml
│ ├── prometheus-serviceAccount.yaml
│ └── prometheus-serviceMonitor.yaml
├── prometheusAdapter
│ ├── prometheusAdapter-apiService.yaml
│ ├── prometheusAdapter-clusterRole.yaml
│ ├── prometheusAdapter-clusterRoleAggregatedMetricsReader.yaml
│ ├── prometheusAdapter-clusterRoleBinding.yaml
│ ├── prometheusAdapter-clusterRoleBindingDelegator.yaml
│ ├── prometheusAdapter-clusterRoleServerResources.yaml
│ ├── prometheusAdapter-configMap.yaml
│ ├── prometheusAdapter-deployment.yaml
│ ├── prometheusAdapter-podDisruptionBudget.yaml
│ ├── prometheusAdapter-roleBindingAuthReader.yaml
│ ├── prometheusAdapter-service.yaml
│ ├── prometheusAdapter-serviceAccount.yaml
│ └── prometheusAdapter-serviceMonitor.yaml
├── prometheusOperator
│ ├── prometheusOperator-clusterRole.yaml
│ ├── prometheusOperator-clusterRoleBinding.yaml
│ ├── prometheusOperator-deployment.yaml
│ ├── prometheusOperator-prometheusRule.yaml
│ ├── prometheusOperator-service.yaml
│ ├── prometheusOperator-serviceAccount.yaml
│ └── prometheusOperator-serviceMonitor.yaml
└── setup
├── 0alertmanagerConfigCustomResourceDefinition.yaml
├── 0alertmanagerCustomResourceDefinition.yaml
├── 0podmonitorCustomResourceDefinition.yaml
├── 0probeCustomResourceDefinition.yaml
├── 0prometheusCustomResourceDefinition.yaml
├── 0prometheusruleCustomResourceDefinition.yaml
├── 0servicemonitorCustomResourceDefinition.yaml
├── 0thanosrulerCustomResourceDefinition.yaml
└── namespace.yaml
10 directories, 85 files然后修改文件grafana-deployment.yaml,按照下面的内容重新定义grafana-storage这个volume。
from
...
volumes:
- emptyDir: {}
name: grafana-storage
...to
...
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
...完整文件参考:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 8.3.3
name: grafana
namespace: monitoring
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
template:
metadata:
annotations:
checksum/grafana-config: 8a40383dc6577c8b30c5bf006ba9ab7e
checksum/grafana-dashboardproviders: cf4ac6c4d98eb91172b3307d9127acc5
checksum/grafana-datasources: 2e669e49f44117d62bc96ea62c2d39d3
labels:
app.kubernetes.io/component: grafana
app.kubernetes.io/name: grafana
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 8.3.3
spec:
containers:
- env: []
image: grafana/grafana:8.3.3
name: grafana
ports:
- containerPort: 3000
name: http
readinessProbe:
httpGet:
path: /api/health
port: http
resources:
limits:
cpu: 200m
memory: 200Mi
requests:
cpu: 100m
memory: 100Mi
volumeMounts:
- mountPath: /var/lib/grafana
name: grafana-storage
readOnly: false
- mountPath: /etc/grafana/provisioning/datasources
name: grafana-datasources
readOnly: false
- mountPath: /etc/grafana/provisioning/dashboards
name: grafana-dashboards
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/alertmanager-overview
name: grafana-dashboard-alertmanager-overview
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/apiserver
name: grafana-dashboard-apiserver
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/cluster-total
name: grafana-dashboard-cluster-total
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/controller-manager
name: grafana-dashboard-controller-manager
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-cluster
name: grafana-dashboard-k8s-resources-cluster
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-namespace
name: grafana-dashboard-k8s-resources-namespace
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-node
name: grafana-dashboard-k8s-resources-node
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-pod
name: grafana-dashboard-k8s-resources-pod
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-workload
name: grafana-dashboard-k8s-resources-workload
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/k8s-resources-workloads-namespace
name: grafana-dashboard-k8s-resources-workloads-namespace
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/kubelet
name: grafana-dashboard-kubelet
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/namespace-by-pod
name: grafana-dashboard-namespace-by-pod
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/namespace-by-workload
name: grafana-dashboard-namespace-by-workload
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/node-cluster-rsrc-use
name: grafana-dashboard-node-cluster-rsrc-use
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/node-rsrc-use
name: grafana-dashboard-node-rsrc-use
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/nodes
name: grafana-dashboard-nodes
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/persistentvolumesusage
name: grafana-dashboard-persistentvolumesusage
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/pod-total
name: grafana-dashboard-pod-total
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/prometheus-remote-write
name: grafana-dashboard-prometheus-remote-write
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/prometheus
name: grafana-dashboard-prometheus
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/proxy
name: grafana-dashboard-proxy
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/scheduler
name: grafana-dashboard-scheduler
readOnly: false
- mountPath: /grafana-dashboard-definitions/0/workload-total
name: grafana-dashboard-workload-total
readOnly: false
- mountPath: /etc/grafana
name: grafana-config
readOnly: false
nodeSelector:
kubernetes.io/os: linux
securityContext:
fsGroup: 65534
runAsNonRoot: true
runAsUser: 65534
serviceAccountName: grafana
volumes:
- name: grafana-storage
persistentVolumeClaim:
claimName: grafana-pvc
- name: grafana-datasources
secret:
secretName: grafana-datasources
- configMap:
name: grafana-dashboards
name: grafana-dashboards
- configMap:
name: grafana-dashboard-alertmanager-overview
name: grafana-dashboard-alertmanager-overview
- configMap:
name: grafana-dashboard-apiserver
name: grafana-dashboard-apiserver
- configMap:
name: grafana-dashboard-cluster-total
name: grafana-dashboard-cluster-total
- configMap:
name: grafana-dashboard-controller-manager
name: grafana-dashboard-controller-manager
- configMap:
name: grafana-dashboard-k8s-resources-cluster
name: grafana-dashboard-k8s-resources-cluster
- configMap:
name: grafana-dashboard-k8s-resources-namespace
name: grafana-dashboard-k8s-resources-namespace
- configMap:
name: grafana-dashboard-k8s-resources-node
name: grafana-dashboard-k8s-resources-node
- configMap:
name: grafana-dashboard-k8s-resources-pod
name: grafana-dashboard-k8s-resources-pod
- configMap:
name: grafana-dashboard-k8s-resources-workload
name: grafana-dashboard-k8s-resources-workload
- configMap:
name: grafana-dashboard-k8s-resources-workloads-namespace
name: grafana-dashboard-k8s-resources-workloads-namespace
- configMap:
name: grafana-dashboard-kubelet
name: grafana-dashboard-kubelet
- configMap:
name: grafana-dashboard-namespace-by-pod
name: grafana-dashboard-namespace-by-pod
- configMap:
name: grafana-dashboard-namespace-by-workload
name: grafana-dashboard-namespace-by-workload
- configMap:
name: grafana-dashboard-node-cluster-rsrc-use
name: grafana-dashboard-node-cluster-rsrc-use
- configMap:
name: grafana-dashboard-node-rsrc-use
name: grafana-dashboard-node-rsrc-use
- configMap:
name: grafana-dashboard-nodes
name: grafana-dashboard-nodes
- configMap:
name: grafana-dashboard-persistentvolumesusage
name: grafana-dashboard-persistentvolumesusage
- configMap:
name: grafana-dashboard-pod-total
name: grafana-dashboard-pod-total
- configMap:
name: grafana-dashboard-prometheus-remote-write
name: grafana-dashboard-prometheus-remote-write
- configMap:
name: grafana-dashboard-prometheus
name: grafana-dashboard-prometheus
- configMap:
name: grafana-dashboard-proxy
name: grafana-dashboard-proxy
- configMap:
name: grafana-dashboard-scheduler
name: grafana-dashboard-scheduler
- configMap:
name: grafana-dashboard-workload-total
name: grafana-dashboard-workload-total
- name: grafana-config
secret:
secretName: grafana-configPrometheus数据持久化
修改prometheus-prometheus.yaml文件,在spec对象下添加以下内容
spec:
storage:
volumeClaimTemplate:
spec:
storageClassName: nfs-client
resources:
requests:
storage: 20Gi完整文件参考:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.32.1
name: k8s
namespace: monitoring
spec:
storage:
volumeClaimTemplate:
spec:
storageClassName: nfs-client
resources:
requests:
storage: 20Gi
alerting:
alertmanagers:
- apiVersion: v2
name: alertmanager-main
namespace: monitoring
port: web
enableFeatures: []
externalLabels: {}
image: quay.io/prometheus/prometheus:v2.32.1
nodeSelector:
kubernetes.io/os: linux
podMetadata:
labels:
app.kubernetes.io/component: prometheus
app.kubernetes.io/instance: k8s
app.kubernetes.io/name: prometheus
app.kubernetes.io/part-of: kube-prometheus
app.kubernetes.io/version: 2.32.1
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
probeNamespaceSelector: {}
probeSelector: {}
replicas: 2
resources:
requests:
memory: 400Mi
ruleNamespaceSelector: {}
ruleSelector: {}
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: 2.32.1
暴露服务
暴露服务到集群外有多种方法,NodePort,Ingress,自己部署Nginx对ClusterIP做反向代理,这里选择相比之下比较简单的NodePort来实现。nodePort默认允许的范围:30000-32767
Prometheus Service
根据下面内容修改prometheus-service.yaml
apiVersion: v1
kind: Service
metadata:
...
name: prometheus-k8s
namespace: monitoring
spec:
ports:
- name: web
port: 9090
targetPort: web
# 这里可以更改为允许的任意端口
nodePort: 30090
- name: reloader-web
port: 8080
targetPort: reloader-web
# 指定Service type
type: NodePort
...Alertmanager Service
根据下面内容修改alertmanager-service.yaml
apiVersion: v1
kind: Service
metadata:
...
name: alertmanager-main
namespace: monitoring
spec:
ports:
- name: web
port: 9093
targetPort: web
# 这里可以更改为允许的任意端口
nodePort: 30093
- name: reloader-web
port: 8080
targetPort: reloader-web
# 指定Service type
type: NodePort
...Grafana Service
根据下面内容修改grafana-service.yaml
apiVersion: v1
kind: Service
metadata:
...
name: grafana
namespace: monitoring
spec:
ports:
- name: http
port: 3000
targetPort: http
# 这里可以更改为允许的任意端口
nodePort: 30003
# 指定Service type
type: NodePort
...启动
setup目录中的yaml文件会创建CRD(CustomResourceDefinition),所以需要提前执行,其余的先后次序无要求。
kubectl create -f setup
kubectl apply -f alertmanager -f blackboxExporter -f grafana -f kubeStateMetrics -f kubernetesControlPlane -f nodeExporter -f prometheus -f prometheusAdapter -f prometheusOperator等待片刻,查看Pod状态,所有Pod状态都是Running的时候,表示服务都已正常启动 
➜ ~ kubectl get pod -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 4d
alertmanager-main-1 2/2 Running 0 4d
alertmanager-main-2 2/2 Running 0 4d
blackbox-exporter-6b79c4588b-9gd2q 3/3 Running 0 4d
grafana-7cbbbdbf77-qwdng 1/1 Running 0 4d
kube-state-metrics-56b4d9b89d-nf6zv 3/3 Running 0 4d
node-exporter-9rk4r 2/2 Running 0 4d
node-exporter-dncwr 2/2 Running 0 4d
node-exporter-mxwj5 2/2 Running 0 4d
node-exporter-qgv9m 2/2 Running 0 4d
node-exporter-z8tqk 2/2 Running 0 4d
prometheus-adapter-849f459d9c-jvj85 1/1 Running 0 4d
prometheus-adapter-849f459d9c-tjxgf 1/1 Running 0 4d
prometheus-k8s-0 2/2 Running 0 4d
prometheus-k8s-1 2/2 Running 0 4d
prometheus-operator-6dc9f66cb7-wzgv4 2/2 Running 0 4d查看Service
➜ ~ kubectl get svc -n monitoring | grep NodePort
alertmanager-main NodePort 10.101.252.191 <none> 9093:30093/TCP,8080:30698/TCP 4d1h
grafana NodePort 10.107.241.77 <none> 3000:30003/TCP 4d
prometheus-k8s NodePort 10.105.187.184 <none> 9090:30090/TCP,8080:31749/TCP 3d23hWeb展示
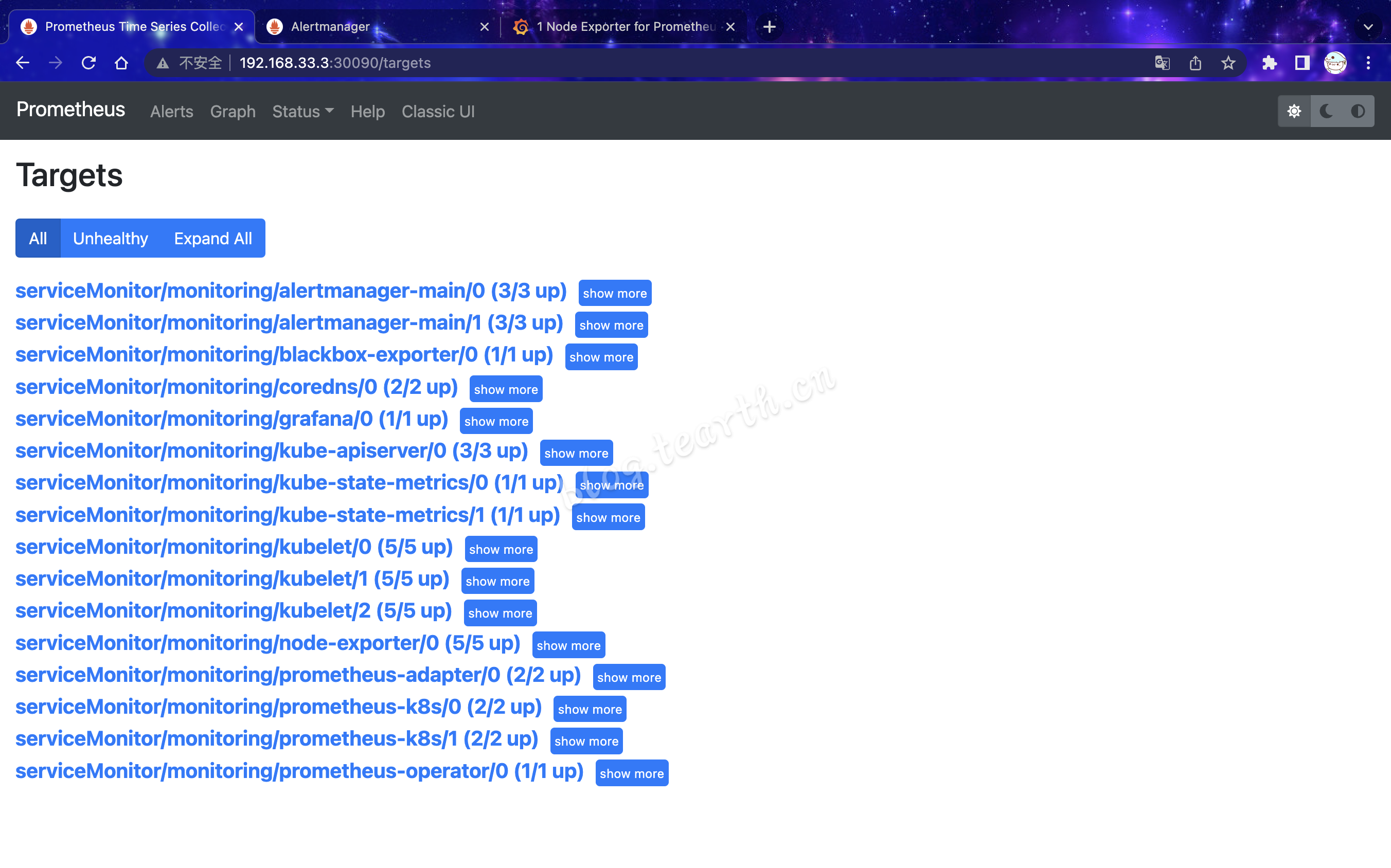
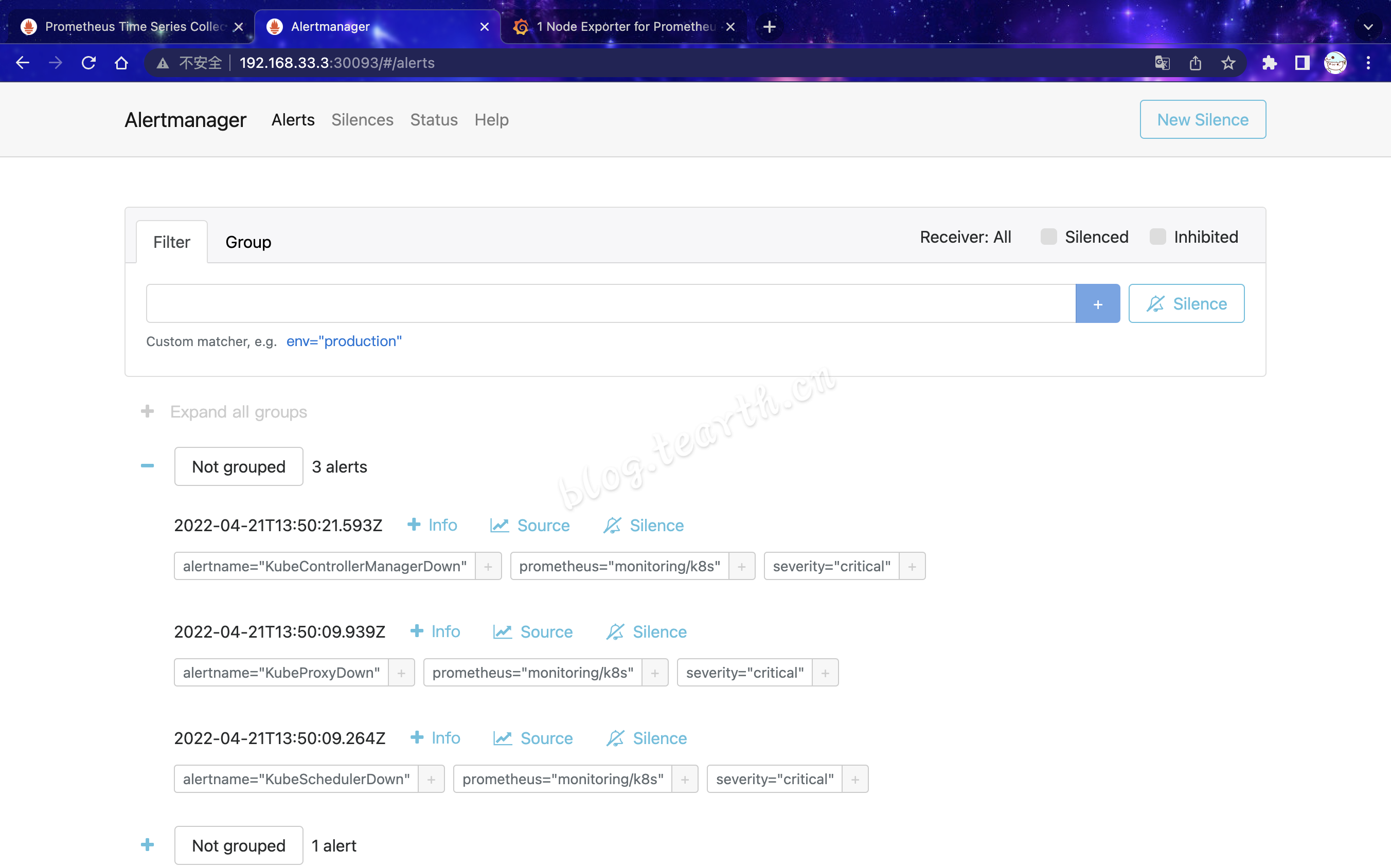
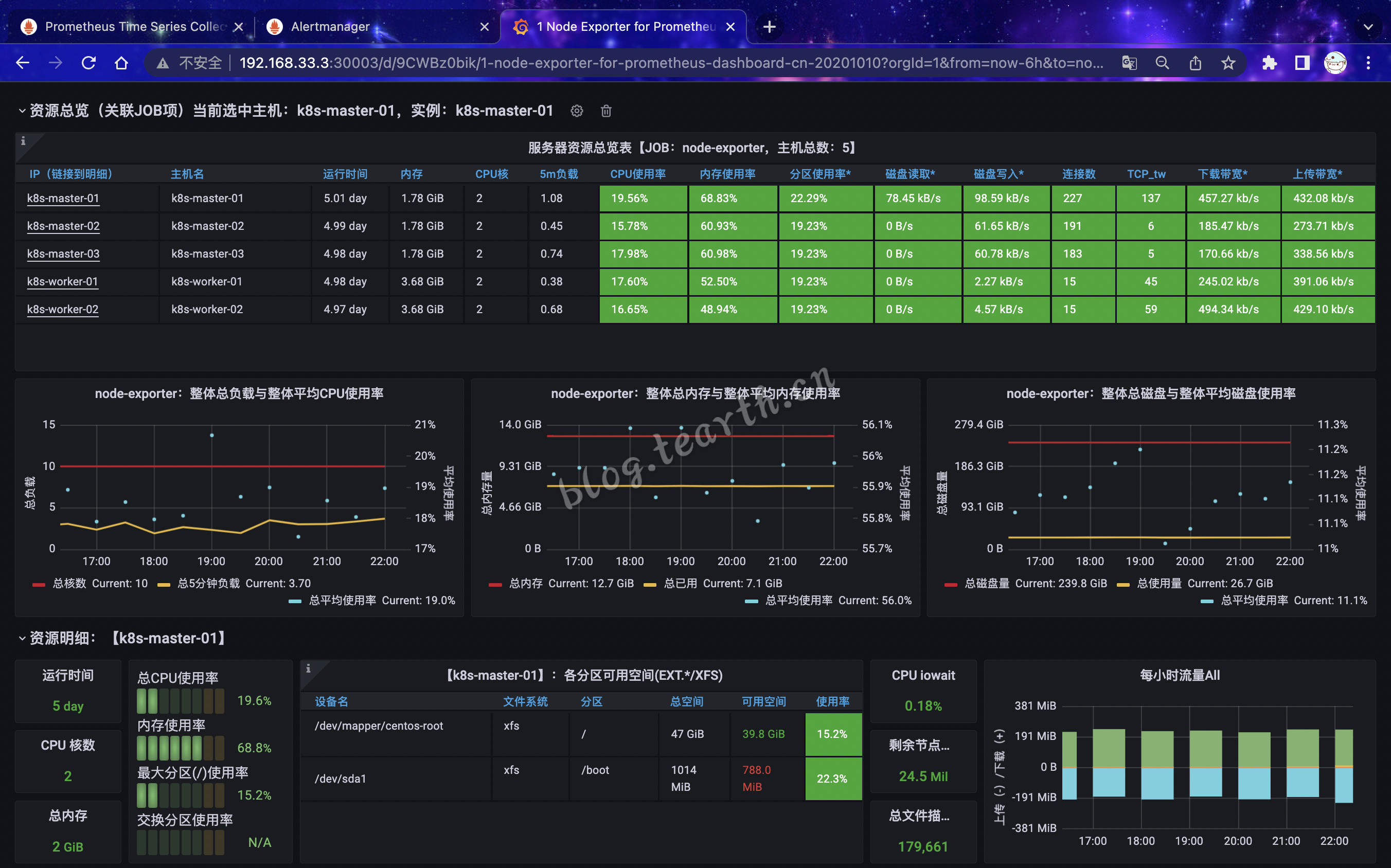
可以看到,Kube-Prometheus默认已对k8s集群内的机器进行了监控,如何让kube-prometheus也可以去监控其他的集群外部的主机,下篇再说 
